IDVoice (speaker verification)
False rejection and false acceptance¶
In voice biometrics there are two main errors, namely "false acceptance" (FA) and "false rejection" (FR).
False acceptance is a situation in which a speaker with a different voice successfully passes verification. False rejection is when a valid speaker with the same voice fails to pass verification. Depending on the thresholds selected by the implementors a system may operate with very low FA but will suffer with excessive FR, in other cases very low FR will result in quite big amount of FA.
In many business scenarios the cost of FA error is much higher of FR error. For example, authentication used to control access to important resource has quite high FA cost, while FR could simply trigger the user to try another authentication attempt or use other means of gaining access.
For these scenarios implementors should understand and control the thresholds on 'successful match' in regard to expected FA/FR. In other words, one should be able to set the score threshold such that expected FA is for example 0.1% and know which FR one should expect in this case. Values of 5% might be entirely acceptable for specific scenario.
Audio quality checking¶
Speech quality checking¶
Quality checks for speech samples during the enrollment process is of great importance for providing the voice template of the highest possible quality to ensure efficient biometric verification. As a minimum such checks should include net speech length evaluation and signal-to-noise ratio estimation. Although speech evaluations could be implemented separately with a set of tools for speech analysis component from Voice SDK Media components (see Signal validation utilities) the more convenient and less error-prone approach is offered by utilising the CheckQuality method of QualityCheckEngine class which is present in the Media component.
There are two checks performed by CheckQuality method of the QualityCheckEngine:
- check if the amount of net speech in recording surpasses the minimum value
- check if the signal-to-noise ratio (level of desired signal to the power of background noise) surpasses the minimum value
The minimum values thresholds which must be surpassed are explicitly set as the parameters of the CheckQuality method, within QualityCheckMetricsThresholds class instance. Recommendations for the default values of the thresholds can be found in IDVoice best practices guideline.
Quality checks are required during the enrollment session before adding speech samples to the user template. Here is a simplified description of the enrollment flow including audio quality checking:
-
Initialise
QualityCheckEngineandVoiceTemplateFactorywith the correct initialization data paths. -
After each enrollment attempt, before adding voice samples to the voice template, pass the path to audio file or the voice data with the sample rate along with minimum values thresholds to the
CheckQualitymethod ofQualityCheckEngineinstance. -
Switch over the
quality_check_short_descriptionto determine the result of the check and proceed accordingly.
The following code snippets show the example of using CheckQuality function in the enrollment flow:
#include <voicesdk/media/quality_check.h>
// ...
voicesdk::QualityCheckEngine::Ptr engine = voicesdk::QualityCheckEngine::Create("/path/to/init_data");
// set thresholds for signal-to-noise ratio and speech length
voicesdk::QualityCheckMetricsThresholds thresholds;
thresholds.minimum_snr_db = <signal-to-noise ratio minimum value that must be surpassed, dB>;
thresholds.minimum_speech_length_ms = <amount of speech in recording that must be surpassed, ms>;
// we assume that voice sample is provided within a WAV file
// check audio quality
voicesdk::QualityCheckEngineResult quality = engine->CheckQuality("/path/to/wav/file", thresholds);
switch (quality.quality_check_short_description) {
case voicesdk::QualityCheckEngineResult::QualityCheckShortDescription::kTooNoisy:
// ask user to repeat the recording in more quiet conditions
break;
case voicesdk::QualityCheckEngineResult::QualityCheckShortDescription::kTooSmallSpeechLength:
// ask user to repeat the recording and provide more net speech
break;
case voicesdk::QualityCheckEngineResult::QualityCheckShortDescription::kOk:
// audio quality is sufficient, audio can be used for enrollment
break;
}
// ...
import net.idrnd.voicesdk.media.QualityCheckEngine;
import net.idrnd.voicesdk.media.QualityCheckEngineResult;
import net.idrnd.voicesdk.verify.QualityCheckShortDescription;
// ...
QualityCheckEngine engine = new VoiceTemplateFactory("/path/to/init_data");
// set thresholds for signal-to-noise ratio and speech length
QualityCheckMetricsThresholds thresholds = new QualityCheckMetricsThresholds(<signal-to-noise ratio minimum value that must be surpassed, dB>, <amount of speech in recording that must be surpassed, ms>);
// we assume that voice sample is provided within a WAV file
// check audio quality
QualityCheckEngineResult quality = engine->checkQuality("/path/to/wav/file", thresholds);
switch (quality.getQualityCheckShortDescription()) {
case QualityCheckShortDescription.TOO_NOISY:
// ask user to repeat the recording in more quiet conditions
break;
case QualityCheckShortDescription.TOO_SMALL_SPEECH_TOTAL_LENGTH:
// ask user to repeat the recording and provide more net speech
break;
case QualityCheckShortDescription.OK:
// audio quality is sufficient, audio can be used for enrollment
break;
}
// ...
from voicesdk_cc.media import QualityCheckEngine, QualityCheckMetricsThresholds, QualityCheckShortDescription
# ...
engine = QualityCheckEngine("/path/to/init_data")
# set thresholds for signal-to-noise ratio and speech length
thresholds = QualityCheckMetricsThresholds(minimum_snr_db=<signal-to-noise ratio minimum value that must be surpassed, dB>,
minimum_speech_length_ms=<amount of speech in recording that must be surpassed, ms>)
# we assume that voice sample is provided within a WAV file
# check audio quality before creating voice template
quality = engine.check_quality("/path/to/wav/file", thresholds)
if quality.quality_check_short_description == QualityCheckShortDescription.TOO_NOISY:
# ask user to repeat the recording in more quiet conditions
# ...
elif quality.quality_check_short_description == QualityCheckShortDescription.TOO_SMALL_SPEECH_TOTAL_LENGTH:
# ask user to repeat the recording and provide more net speech
# ...
else:
# audio quality is sufficient, audio can be used for enrollment
# ...
# ...
Template matching check for Text Dependent enrollment¶
Typical text-dependent voice enrollment session consists of 3-5 separate recordings of a person pronouncing the pass phrase. Alongside with speech quality checks voice template matching check can also be applied during the enrollment session. Template matching check consists of creating a reference template with VoiceTemplateMatcher class from the first enrollment recording and comparing all subsequent records with the reference template to ensure that they are performed by the same speaker. The described approach serves for enforcing the enrollment session to be performed by a single speaker.
-
Initialise
VoiceTemplateFactoryandVoiceTemplateMatcherwith the correct Initialization data path. -
After passing all speech quality checks create voice template for the first enrollment record and store it as a reference template for the rest of the session.
-
Check that each next voice template matches the reference template before appending.
How to create a template and what is it?¶
The Voice Template is a result of enrollment process in enroll/verify scenario. It is an opaque sequence of bytes that corresponds to the speech of the enrolled person and is later used in verification process. The voice template is typically very small and can be stored independently of the audio files it was produced from, which makes it ideal for permanent on-chip storage.
IDVoice CC engine contains the following enrollment/verification methods:
- tel-3, which is designed for both text-dependent and text-independent voice verification scenarios in microphone channel.
Ways of creating a typical voice template¶
As noted above, the good scenario is to enroll in quiet place without other voices in background. Enrolling person should speak clearly. Verification then can be done even in noisy conditions.
VoiceTemplateFactory class provides voice template creation capabilities. A voice template is created by calling VoiceTemplateFactory::createVoiceTemplate(...) method in any supported programming language. You can either create a template from the audio file, or from ready samples in form of bytes, shorts or normalized floats. Each language wrapper supports these overloads as well.
Code samples below illustrate creating a voice template using WAV file:
#include <voicesdk/verify/verify.h>
// ...
VoiceTemplateFactory::Ptr factory = VoiceTemplateFactory::create("/path/to/init_data");
// create voice template from wav file.
// you don't need to re-initialize the factory for creating next templates
VoiceTemplate::Ptr voiceTmpl = factory->createVoiceTemplate("/path/to/wav/file");
import net.idrnd.voicesdk.verify.VoiceTemplateFactory;
import net.idrnd.voicesdk.core.common.VoiceTemplate;
// ...
VoiceTemplateFactory factory = new VoiceTemplateFactory("/path/to/init_data");
// create voice template from wav file.
// you don't need to re-initialize the factory for creating next templates
VoiceTemplate voiceTmpl = factory.createVoiceTemplate("/path/to/wav/file");
from voicesdk_cc.verify import VoiceTemplateFactory
from voicesdk_cc.core import VoiceTemplate
# ...
factory = VoiceTemplateFactory("/path/to/init_data")
# create voice template from wav file.
# you don't need to re-initialize the factory for creating next templates
voice_template = factory.create_voice_template_from_file("/path/to/wav/file")
Typical enrollment examples that are used in the real-world scenarios:
-
Asking a user to speak one phrase 3-5 times and produce merged template out of three distinct templates. This template is then used as a verification passphrase in text-dependent verification when a sensitive action is pending.
-
Asking a user to read part of the text for 15-20 seconds to produce one template. This template is then used to verify any speech provided in text-independent verification.
How to perform verification (template matching)¶
Note that the process of converting audio file to voice template is what takes most of the processing time. Matching two pre-converted templates with each other is very fast on any given hardware.
It's also advised to cache templates that are created from known files so that they won't need to be created anew once the need arises. This may help if you have a large database of existing customer voices.
VoiceTemplateMatcher class provides voice template matching capabilities. Two voice templates can be matched with each other by calling VoiceTemplateMatcher::matchVoiceTemplates(template1, template2). Resulting score and probability indicate how close the voices (and passphrases in text-dependent case) are.
Code samples below illustrate matching two voice templates:
#include <voicesdk/verify/verify.h>
// ...
const std::string initDataPath = "/path/to/init/data/tel-3";
// use the same init data for both factory and matcher
VoiceTemplateFactory::Ptr factory = VoiceTemplateFactory::create(initDataPath);
VoiceTemplateMatcher::Ptr matcher = VoiceTemplateMatcher::create(initDataPath);
// create voice templates
VoiceTemplatePtr voiceTmpl1 = factory->createVoiceTemplate("/path/to/wav/file1");
VoiceTemplatePtr voiceTmpl2 = factory->createVoiceTemplate("/path/to/wav/file2");
// match voice templates
VerifyResult verifyResult = matcher->matchVoiceTemplates(voiceTmpl1, voiceTmpl2);
// output the resulting score and probability
std::cout << std::fixed; // for better float formatting
std::cout << verifyResult << std::endl;
import net.idrnd.voicesdk.verify.VoiceTemplateFactory;
import net.idrnd.voicesdk.verify.VoiceTemplateMatcher;
import net.idrnd.voicesdk.core.common.VoiceTemplate;
// ...
String initDataPath = "/path/to/init/data/tel-3";
// use the same init data for both factory and matcher
VoiceTemplateFactory factory = new VoiceTemplateFactory(initDataPath);
VoiceTemplateMatcher matcher = new VoiceTemplateMatcher(initDataPath);
// create voice templates
VoiceTemplate voiceTmpl1 = factory.createVoiceTemplate("/path/to/wav/file1");
VoiceTemplate voiceTmpl2 = factory.createVoiceTemplate("/path/to/wav/file2");
// match voice templates
System.out.println("Results follow:");
VerifyResult result = matcher.matchVoiceTemplates(voiceTmpl1, voiceTmpl2);
System.out.println(String.format("Verification result: %s", result));
from voicesdk_cc.verify import VoiceTemplateFactory, VoiceTemplateMatcher
from voicesdk_cc.core import VoiceTemplate
# ...
init_data_path = "/path/to/init/data/tel-3"
// use the same init data for both factory and matcher
factory = VoiceTemplateFactory(init_data_path)
matcher = VoiceTemplateMatcher(init_data_path)
# create voice templates
voice_template1 = factory.create_voice_template_from_file("/path/to/wav/file1")
voice_template2 = factory.create_voice_template_from_file("/path/to/wav/file2")
# match voice templates
res = matcher.match_voice_templates(voice_template1, voice_template2)
print("Verification result: ", res)
Outputs: Scores and Probabilities¶
At the end of the verification process, either a score or probability is returned depending on the function used. In each case, higher values indicate greater similarity.
In the general case it is recommended to use probability value for making a decision. A typical threshold value for matching probability is 0.5. This value provides the optimal balance between FA and FR rates (i.e. these errors are roughly equal when using this threshold value).
Since distributions for Scores and Probabilities vary based on each dataset, you may wish to observe score distributions across your test dataset to determine the most appropriate threshold for each verification/comparison method you use. Each method may need to be tuned individually if the system defaults are not acceptable.
At a high level, these thresholds can be determined using an existing dataset.
-
If you have a labeled target/imposter dataset you can perform cross-matching between all the templates and select a threshold score that will serve as a barrier between target speakers and imposters. This value can depend on the signal-to-noise ratio and audio quality of your dataset.
-
If you do not have a labelled dataset, you can perform a similar evaluation by matching a voice template against all templates including itself. Matching a template with itself will produce a high score, with lower scores for other templates.
Continuous speaker verification¶
IDVoice CC SDK offers a special feature to perform continuous text-independent speaker verification using an audio stream. Typical use case for this capability is a call center scenario. Imagine that call center operator receives a call from a phone number which is enrolled to the call center database as belonging to a specific customer. Let's assume that this call center belongs to a bank, and the customer is calling in order to make some changes to their bank account. Of course, it can't be done without some kind of identity confirmation, which is usually implemented with a code phrase. Modern call center solutions offer confirmation by voice, which requires customer to pronounce their code phrase. Unfortunately, this way to confirm customer identity may be inefficient in terms of time spent by operator, because operator spends several minutes even if the call was made by a fraudster. The described feature solves this issue since it enables real time customer identity confirmation from the very beginning of the call, so it saves time and efforts for the operator, and also improves user experience for the customer.
Please see the flow diagram explaining the continuous speaker verification procedure implemented in IDVoice CC SDK below.
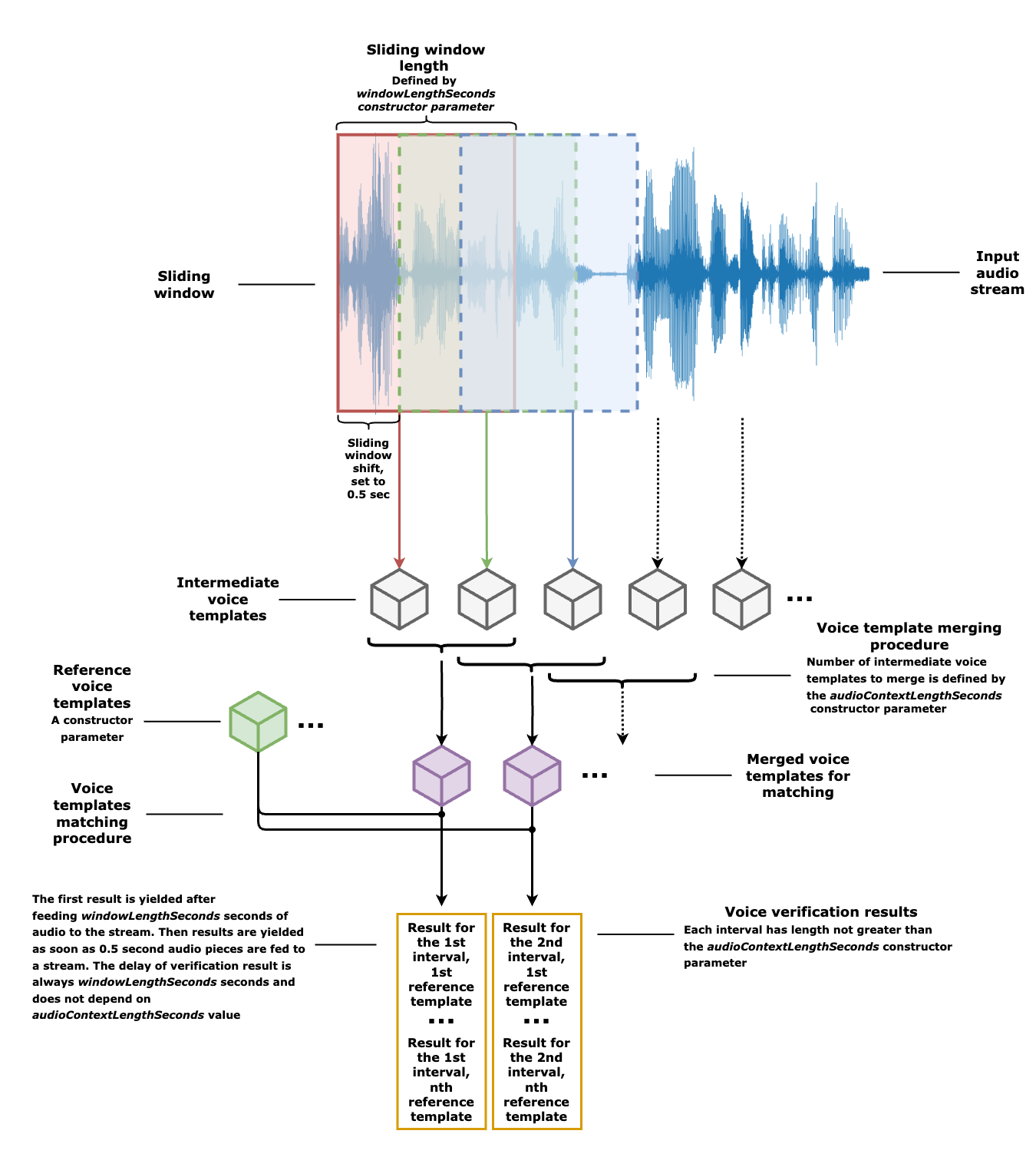
VoiceVerifyStream class requires several parameters for initialization:
- Voice template factory instance.
- Voice template matcher instance.
- Input audio stream sampling rate.
- Target voice template to compare with.
- Averaging window width in seconds.
The last parameter defines the "memory" of the stream and also provides a way to manage the level of the stream "confidence" (which amount of good matching audio is required for stream to be confident about the claimed speaker identity). The default value is 10 seconds, and it is also recommended for a call center scenario. It can be decreased to 5-8 seconds based on the user experience.
Python code sample below illustrates using voice verification stream:
import numpy as np
import pyaudio
from voicesdk_cc.verify import VoiceTemplateFactory, VoiceTemplateMatcher
from voicesdk_cc.core import VoiceTemplate
# 0.1. Init voice template factory and matcher
init_data_path = "/path/to/init/data"
factory = VoiceTemplateFactory(init_data_path)
matcher = VoiceTemplateMatcher(init_data_path)
# 0.2. Set recording params
sample_rate = 16000
buffer_length_samples = 1024
# 1. Create voice template using the provided enrollment WAV file
template = factory.create_voice_template_from_file("<path to the enrollment WAV file>")
# 2. Create verify stream
verify_stream = VoiceVerifyStream(factory, matcher, template, sample_rate)
# 3. Perform streaming verification
input("Press enter key to start recording")
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16, channels=1, rate=sample_rate, input=True, frames_per_buffer=buffer_length_samples)
print("Press Ctrl-C to exit")
print("Recording...")
while True:
# 3.1. Feed a chunk of size ‘buffer_length_samples’ of a captured signal to verify_stream
audio_samples = np.frombuffer(stream.read(buffer_length_samples), dtype=np.int16)
verify_stream.add_samples(audio_samples)
# 3.2. Check if stream produced verification results, retrieve them if there are any
while verify_stream.has_verify_results():
print(verify_stream.get_verify_result())
stream.close()